Reasoning Language Models: Un Blueprint para Democratizar la IA de Razonamiento
Los Reasoning Language Models (RLMs) representan uno de los avances más significativos en inteligencia artificial desde la llegada de ChatGPT. Modelos como OpenAI's o1 y o3, DeepSeek-R1, y Alibaba's QwQ han redefinido las capacidades de resolución de problemas de la IA, extendiendo los modelos de lenguaje grandes (LLMs) con mecanismos avanzados de razonamiento que nos acercan más a la AGI (Artificial General Intelligence).
Sin embargo, su alto costo, naturaleza propietaria y arquitecturas complejas presentan desafíos significativos. Un reciente paper de investigadores de ETH Zurich propone un blueprint comprensivo que organiza los componentes de RLMs en un framework modular, democratizando el acceso a estas capacidades avanzadas.
🎯 El Problema: La Brecha entre "Rich AI" y "Poor AI"
Los RLMs de última generación, especialmente los desarrollados por OpenAI, son extremadamente costosos y propietarios. Incluso modelos como QwQ de Alibaba, que son públicamente disponibles, solo proporcionan los pesos del modelo sin revelar detalles sobre sus metodologías de entrenamiento o generación de datos.
Esta situación crea una creciente brecha entre organizaciones e individuos que pueden permitirse estos sistemas avanzados y aquellos que no, amenazando con sofocar la innovación, reforzar inequidades sistémicas y limitar el progreso en aplicaciones críticas.
🧠 ¿Qué son los Reasoning Language Models?
Los RLMs combinan tres pilares fundamentales que convergen para crear sistemas de razonamiento avanzados. El siguiente diagrama ilustra cómo estos pilares se integran:
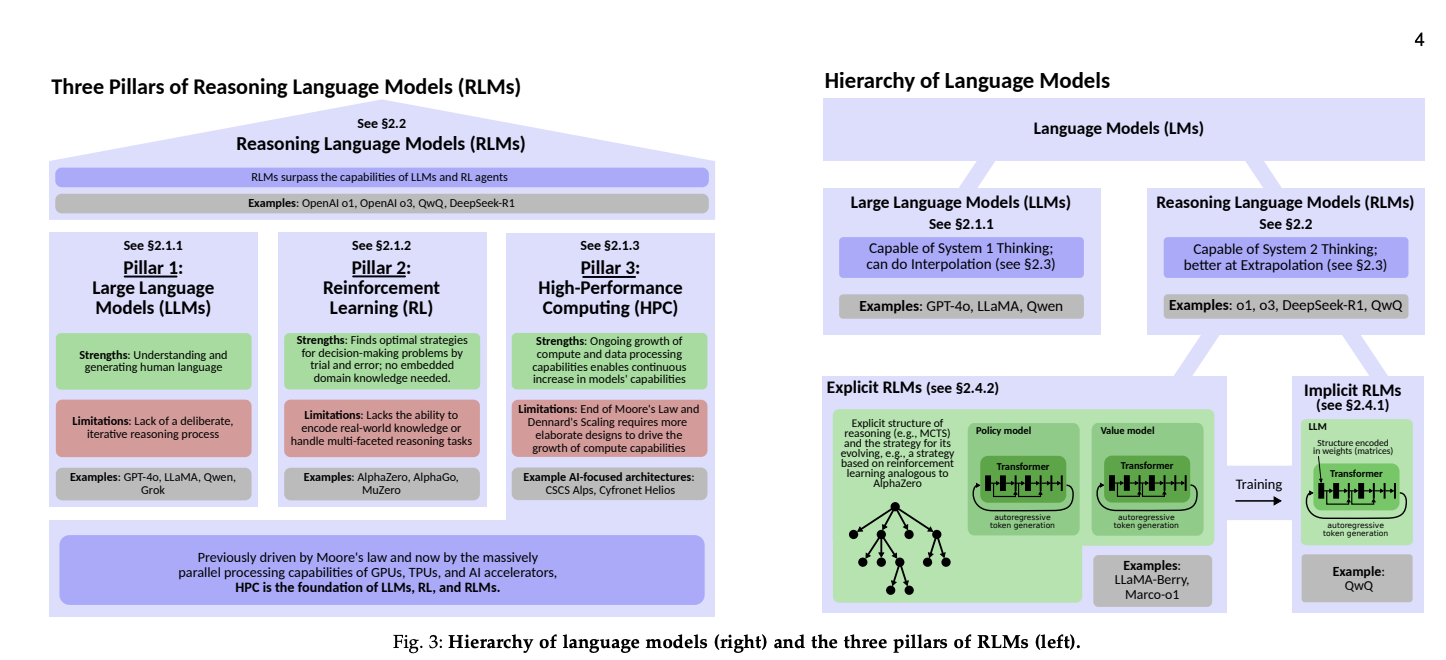
Diagrama: Los tres pilares fundamentales de los RLMs - Large Language Models (LLMs), Reinforcement Learning (RL) y High-Performance Computing (HPC) - y cómo convergen para crear sistemas de razonamiento avanzados.
1. Large Language Models (LLMs) - Un Reservorio de Conocimiento
Los LLMs como GPT-4o o LLaMA representan un salto extraordinario en IA, constituyendo un vasto repositorio de conocimiento mundial codificado directamente en sus pesos. Sin embargo, su razonamiento se alinea principalmente con el System 1 Thinking (rápido, automático e intuitivo), mientras que los RLMs buscan lograr el System 2 Thinking (deliberado, explícito y estructurado).
Características clave:
- Entrenados en enormes corpus de texto de diversas fuentes
- Capaces de entender y generar lenguaje humano con fluidez notable
- Limitados a razonamiento superficial basado en predicción estadística
- Realizan principalmente interpolación dentro del espacio de soluciones conocido
2. Reinforcement Learning (RL) - Exploración e Innovación
El RL ha proporcionado históricamente un framework para toma de decisiones y exploración. Sistemas emblemáticos como AlphaZero demostraron el potencial del RL logrando rendimiento sobrehumano en juegos como ajedrez, shogi y Go.
Fortalezas del RL:
- Encuentra estrategias óptimas mediante prueba y error
- No requiere conocimiento de dominio embebido
- Puede descubrir soluciones innovadoras fuera de la intuición humana
- Navega eficientemente espacios de búsqueda vastos
Limitaciones históricas:
- Los sistemas tradicionales de RL carecían de la capacidad de codificar conocimiento del mundo real
- No podían manejar tareas de razonamiento complejas y multifacéticas
- Esta limitación impulsó la integración de principios de RL con LLMs
3. High-Performance Computing (HPC) - El Motor del Progreso
El crecimiento continuo del poder computacional, impulsado por GPUs, TPUs y aceleradores de IA, ha habilitado el desarrollo de estos modelos complejos.
Evolución clave:
- De la era Petascale (Titan, Piz Daint) a la era Exascale (CSCS Alps, Cyfronet Helios)
- Aceleradores especializados: V100 → A100 → H100 → GB200 → GH200
- Innovaciones en eficiencia: esparcidad, cuantización, poda y paralelismo distribuido
🏗️ Arquitectura de los RLMs: Componentes Especializados
Los RLMs emplean múltiples componentes especializados que trabajan en conjunto. La arquitectura general consiste en tres pipelines principales:
- Pipeline de Inferencia: Sirve las solicitudes de los usuarios usando modelos entrenados
- Pipeline de Entrenamiento: Entrena los modelos usando datos generados
- Pipeline de Generación de Datos: Genera datos de entrenamiento de alta calidad
Estos pipelines trabajan de manera análoga a sistemas de autoaprendizaje, donde la generación de datos y el entrenamiento se combinan para crear capacidades de autoaprendizaje.
Componentes Principales
- Modelos de Política (Policy Models): LLMs fine-tuneados que generan los mejores pasos de razonamiento subsecuentes, actuando como el "motor de razonamiento"
- Modelos de Valor (Value Models): LLMs que estiman qué tan prometedor es un estado o paso de razonamiento particular
- Modelos de Recompensa (Reward Models): Proporcionan señales de retroalimentación para guiar el aprendizaje
- Motores de Generación de Datos Sintéticos: Crean datos de entrenamiento de alta calidad
🔍 El Blueprint: Un Framework Modular y Flexible
El paper propone un blueprint comprensivo que organiza todos estos componentes en un framework modular. Este blueprint se presenta con tres perspectivas complementarias:
- Diagramas de arquitectura y descripciones - Vista de alto nivel
- Formulaciones matemáticas detalladas - Especificaciones precisas
- Especificaciones algorítmicas en profundidad - Implementación práctica
Estructuras de Razonamiento
El blueprint soporta múltiples estructuras de razonamiento:
- Cadenas (Chains): Razonamiento secuencial paso a paso, como Chain-of-Thought (CoT)
- Árboles (Trees): Exploración de múltiples caminos simultáneamente, como Tree of Thoughts (ToT)
- Grafos (Graphs): Estructuras más complejas que permiten conexiones no lineales
- Formas anidadas: Árboles jerárquicos para razonamiento multi-nivel
Estrategias de Búsqueda
El blueprint incorpora diversas estrategias de búsqueda:
Monte Carlo Tree Search (MCTS): Una de las estrategias más importantes que funciona mediante:
- Selección: Elige el nodo más prometedor basado en estadísticas
- Expansión: Añade nuevos nodos hijos al árbol
- Simulación: Evalúa el nodo expandido
- Retropropagación: Actualiza las estadísticas a lo largo del camino
Beam Search: Mantiene solo las N mejores hipótesis en cada paso, redefiniendo el razonamiento a través de estructuras de cadenas largas implícitas.
Esquemas de Supervisión
El blueprint soporta diferentes esquemas de entrenamiento:
- Outcome-Based Supervision (OBS): Entrenamiento basado únicamente en resultados finales
- Process-Based Supervision (PBS): Entrenamiento basado en el proceso de razonamiento, evaluando cada paso
- Trace-Based Supervision (TBS): Incorpora trazas etiquetadas de caminos completos de razonamiento
🛠️ El Framework x1: Implementación Práctica
Para demostrar la utilidad del blueprint, los investigadores introducen x1, una implementación modular diseñada para simplificar el desarrollo y experimentación con nuevas arquitecturas RLM.
Características principales:
- Cubre todo el ciclo de vida del modelo (entrenamiento e inferencia)
- Generación de datos sintéticos para crear datasets de alta calidad
- Optimizaciones y escalabilidad con procesamiento por lotes
- Facilita despliegues en la nube para investigación y producción
El código está disponible en GitHub, proporcionando una base sólida para investigación y casos de uso en producción.
💡 Insights Clave para Construir RLMs Efectivos
Basándose en el análisis de literatura y experimentación con x1, el paper proporciona insights importantes:
1. Entrenamiento Multi-Fase
Los modelos de política y valor se benefician significativamente de esquemas de entrenamiento en múltiples fases, permitiendo mejor convergencia, optimización incremental y reducción de inestabilidades.
2. Distribuciones de Entrenamiento Familiares
Es crucial usar distribuciones de datos familiares durante el entrenamiento. Los modelos aprenden mejor cuando los datos reflejan el dominio de aplicación y se evitan cambios abruptos que pueden causar "catastrophic forgetting".
3. Interpolación vs Extrapolación
- LLMs (Interpolación): Generan respuestas que se alinean con patrones vistos en sus datos de entrenamiento, limitándose a producir salidas dentro de su distribución de entrenamiento.
- RLMs (Extrapolación): Habilitan extrapolación más allá de estos límites mediante exploración estructurada, generando soluciones novedosas que se extienden más allá de sus datos de entrenamiento.
4. Modelos Explícitos vs Implícitos
- RLMs Implícitos: La estructura de razonamiento está embebida completamente en los pesos del modelo (ej: QwQ). El razonamiento es opaco.
- RLMs Explícitos: Introducen mecanismos de razonamiento externos (ej: LLaMA-Berry, Marco-o1), permitiendo simular, evaluar y refinar soluciones iterativamente.
🚀 Implicaciones para el Futuro
Este trabajo tiene implicaciones significativas:
Democratización de la IA: Al proporcionar un blueprint claro y herramientas prácticas, este trabajo busca mitigar la brecha entre "rich AI" y "poor AI", permitiendo que investigadores independientes y organizaciones con recursos limitados accedan a capacidades avanzadas.
Aceleración de la Innovación: El framework modular facilita la experimentación rápida con nuevos paradigmas de razonamiento, acelerando el progreso en el campo.
Escalabilidad en la Nube: Los despliegues escalables de RLMs en entornos cloud aseguran que estas capacidades puedan integrarse en infraestructura moderna tanto para investigación como para producción.
🎯 Conclusión
Los Reasoning Language Models representan un paso significativo hacia AGI, pero su complejidad y costo han limitado su accesibilidad. El blueprint propuesto en este paper, junto con el framework x1, proporciona un camino claro hacia la democratización de estas capacidades avanzadas.
Puntos clave:
- Los RLMs combinan LLMs, RL y HPC para lograr razonamiento avanzado
- El blueprint modular permite construir RLMs personalizados para diferentes aplicaciones
- El framework x1 facilita la experimentación y el desarrollo práctico
- La democratización de estas tecnologías es crucial para evitar la brecha "rich AI" vs "poor AI"
Para aquellos trabajando en arquitectura cloud, seguridad e IA, este trabajo es particularmente relevante. No solo proporciona insights sobre cómo funcionan estos sistemas avanzados, sino que también ofrece herramientas prácticas para experimentar y construir nuestros propios sistemas de razonamiento.
El futuro de la IA no debería estar limitado a quienes pueden pagar por modelos propietarios. Con frameworks como este, podemos trabajar hacia un futuro donde las capacidades avanzadas de razonamiento sean accesibles para todos.
📚 Referencias y Recursos
- Paper original: arXiv:2501.11223v4 - "Reasoning Language Models: A Blueprint"
- Framework x1: GitHub - spcl/x1 - Implementación modular para RLMs
- Autores: Maciej Besta (corresponding), Julia Barth, Eric Schreiber, y colaboradores de ETH Zurich, Cledar, BASF SE, y Cyfronet AGH
Categorías relacionadas: Inteligencia Artificial, Machine Learning, Arquitectura de Sistemas, Cloud Computing, Reinforcement Learning